websites > surveys > samples > occurrences¶
The main spine of the data model captures species observations and is covered by the websites, surveys, samples, occurrences and determinations tables. The following diagram shows the relationships between these tables as well as the associated custom attribute tables described later on this page:
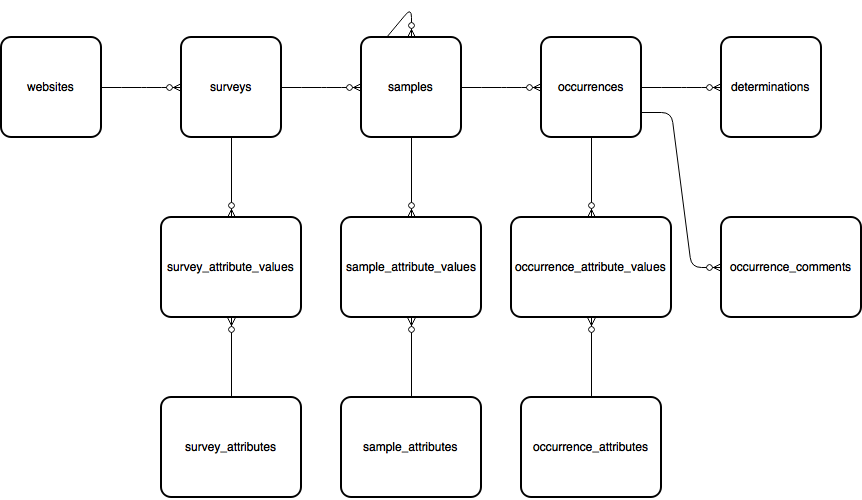
websites¶
All occurrence data in the database are “owned” by the client website which they were entered on. Each client website has an entry in the websites table which allows all the records to be tagged against the website ID which contributed them. By default each website can only view or edit the occurrence data belonging to them, though it is also possible to set up agreements between registered websites that allow the records to be shared. For example, this approach is used to allow multiple websites to share their records to the iRecord verification portal in the UK.
Ref. websites
surveys¶
Within each website registered on the warehouse, data are divided up into survey datasets, each described by a single row in the surveys table. Each survey dataset can have a different set of attributes collected for the records it contains so it makes sense to divide the records into multiple survey datasets based on their purpose and data structure rather than to keep them all together in one. For example, a survey dataset for insect data might collect an attribute for the count of each record, whereas one for plant data might collect a DAFOR abundance value. The configuration of custom attributes available is defined at the level of the survey dataset therefore it is often the case that a survey dataset is created for each recording form you build.
Ref. surveys
samples¶
A sample defines a set of data which were collected by the same recorder(s) on the same date at the same place using the same method. Therefore you would expect to have a sample record created for each grid reference you recorded at during a day of recording. Each sample can contain any number of occurrences (records) and each sample belongs to a survey dataset which defines the additional custom attributes available to record against it.
Note that samples can be hierarchical by pointing the parent_id foreign key field at another sample record. This allows more complex surveying methodologies to be captured, for example a transect sample can capture metadata about the overall transect, then sub-samples can capture the records at exact points along the transect.
Samples capture the entered map reference as both a plain text field (as entered by the recorder) and a spatial object ready for drawing on a map. We’ll cover spatial data in detail in the next section.
Since a sample date can span several days, or may not be precisely known (especially relevant for historic data), sample dates are stored in a 3 field “vague date format” borrowed from Recorder. The first 2 fields are a date_start and date_end field which define the complete range of dates covered by the vague date. They will be the same if a single exact date is provided and one or the other can be null (e.g. when specifying a date before 2009 the start date will be null). The 3rd date_type field is a code which describes what type of date is being given, e.g. an exact day, month, year or date range. You can use the vague_date_to_string(date_start, date_end, date_type) function to convert the date stored in the database into formatted text for display.
The following table shows examples of all vague date types.
Description |
Vague date |
start_date |
end_date |
date_type |
|---|---|---|---|---|
Day |
23 Mar 1987 |
1987-03-23 |
1987-03-23 |
D |
Day range |
23 Mar 1987 to 30 Mar 1987 |
1987-03-23 |
1987-03-30 |
DD |
Month in year |
Mar 1987 |
1987-03-01 |
1987-03-31 |
O |
Month range |
Mar 1987 to Jun 1987 |
1987-03-01 |
1987-06-30 |
OO |
Season in year |
Winter 1987 |
1986-12-01 |
1987-02-28 |
P |
Year |
1987 |
1987-01-01 |
1987-12-31 |
Y |
Year range |
1981 to 1987 |
1981-01-01 |
1987-12-31 |
YY |
Open ended year range |
From 1987 |
1987-01-01 |
<null> |
Y- |
Up to year |
To 1987 |
<null> |
1987-12-31 |
-Y |
Century |
20c |
1901-01-01 |
2000-12-31 |
C |
Century range |
18c to 20c |
1701-01-01 |
2000-12-31 |
CC |
Open ended century range |
From 20c |
1901-01-01 |
<null> |
C- |
Up to century |
To 19c |
<null> |
1900-12-31 |
-C |
Month only |
June |
<current year>-06-01 |
<current year>-06-30 |
M |
Season only |
Summer |
<current year>-06-01 |
<current year>-08-31 |
S |
Unknown |
Unknown |
<null> |
<null> |
U |
Vague dates can be supplied in various forms. All of the following are equivalent:
1997-08-02
02/08/1997
2 August 1997
2 Aug 97
When specifying ranges, the words to and from can be replaced with a hyphen.
Winter is considered the first season of the year. Winter 2020 starts on 1st December, 2019 and ends on 29th February, 2020. Spring, Summer and Autumn follow, starting on the 1st of March, June, and September.
Note that the strict definition of a century is used, not the one that is popularly understood.
Tip
Rarely will you want to mess with the 3 date component fields. If you submit a single field named date to the sample model containing a date in one of the above vague-date formats, it will be correctly interpreted. Likewise, when writing reports, you will see vague dates returned unless you specify otherwise, see Element <vagueDate>
Ref. samples
sample_comments¶
The sample comments contains a log of all comments made regarding a sample, including:
those made by recorders on each others samples
queries made by experts
verification decisions made by experts (if sample verification is enabled)
Ref. developing/data-model/tables:sample-comments
occurrences¶
Each occurrence of a species recorded in the database is stored as a single record in the occurrences table. Occurrences always belong to samples, have a foreign key to the taxon and may have additional custom attributes attached, e.g. for the abundance count.
The following example illustrates this section of the database schema by selecting some simple details from the most recently added record in the database. Note it doesn’t include any taxonomic information - we’ll cover that in a moment.
select o.id,
w.title as website_title,
su.title as survey_title,
s.entered_sref,
vague_date_to_string(s.date_start, s.date_end, s.date_type) as "date"
from websites w
join surveys su on su.website_id=w.id and su.deleted=false
join samples s on s.survey_id=su.id and s.deleted=false
join occurrences o on o.sample_id=s.id and o.deleted=false
where w.deleted=false
order by o.id desc
limit 1
A key aspect of the occurrences table is the ability to easily track the status of a record especially with respect to quality. This is achieved using 2 fields, record_status and record_substatus. The record_status field provides the broad status of the record and the optional record_substatus field provides a greater level of granularity. The record_status has the following possibilities:
V = verified or accepted
C = data entry complete and pending check
R = rejected or not accepted
When the record_status is combined with the record_substatus the possibilities are as follows:
V + null = verified or accepted
V + 1 = verified or accepted as correct (i.e. accepted as beyond reasonable doubt, e.g. if specimen or good photographic evidence available).
V + 2 = verified or accepted as considered correct (i.e. accepted but without photographic or voucher specimen evidence)
C + 3 = data entry complete, checked but not conclusive, marked as plausible.
C + null = data entry complete and pending check
R + 4 = rejected as considered incorrect
R + 5 = rejected as incorrect (i.e. evidence available to prove it is incorrect beyond reasonable doubt).
R + null = rejected or not accepted
Therefore a query to obtain all accepted records can simply filter on record_status=V and ignore the substatus.
Ref. occurrences
occurrence_comments¶
The occurrence comments contains a log of all comments, including:
those made by recorders on each others records
queries made by experts
verification decisions made by experts
comments added by automatic record quality checks, e.g. flagging records outside the expected range or time of year.
Ref. developing/data-model/tables:occurrence-comments
determinations¶
Where there have been multiple opinions on the identification of a record, the determinations table contains previous identification details.
Ref. determinations